Dr Samantha Pendleton
Clinical Informatician
Engineer of data, ontologies, and clusters. Thrower of pots, controllers, and eggs.
Validation of NLP tools and comparison to LLMs
ChatGPT. Now that I have your attention. This isn’t about ChatGPT specifically but rather about the larger picture: Large Language Models (LLMs). ChatGPT is a large language model.
Introduction
Many Natural Language Processing (NLP) tools are perhaps becoming obsolete with the emergence of complex LLMs, most notably ChatGPT.
LLMs have been around for a while but gained attention around 2020 when GPT3 was released by OpenAI1. LLMs are designed to understand human language and are trained on large amounts of text: books, code, social media, clinical documentation, transcripts, and more. These models learn the patterns in language in order to “communicate”. When asked a question, the model observes the tokens (words) you used and based on its knowledge, it’ll generate a response by predicting/arranging tokens in such a way that resembles a conversation.
LLMs don’t actually think or understand these patterns. For example, back in 2020 if you’d ask an LLM for a list of published papers, the model would generate “fake” references based on recognising how citations are typically structured and authors in that research area - rather than providing real, verified sources.
Side note: readers can explore ChatGPT and ask some questions if they haven’t already: https://chatgpt.com/.
Jabberwocky is an NLP toolkit designed to handle unstructured text, with features to implement those nonsensical ontologies2. I have been developing Jabberwocky since 2019 and over time has expanded with more capabilities.
The primary NLP annotation function is Catch that uses a PhraseMatcher() to annotate a corpus with words - or phrases - of interest.
See the GitHub for more information on functionality.
- Annotation
- to add meaningful information to text data. In the context of this article, to indicate whether a specific word is present in a sentence.
Jabberwocky was developed because manually annotating a corpus is an exhaustive task, especially data large in size, and often researchers can miss important information, for example, they may not consider particular synonyms, accidentally skip over lines, or don’t consider the context.
This article aims to compare manual annotation, Jabberwocky’s Catch, and various LLMs to show differences in how manual, computational tools, and an LLM’s ability to annotate text.
Side note: although ChatGPT is mentioned in the name, I won’t be using that specific model and instead use models from Google, Meta, and Mistral. Additionally, I aimed to time each method but the LLMs are being accessed via API requests, after the first 30 requests there are delays and so I decided to average them across models and raise here that they cannot be fairly compared.
- Code
- to see the code, you can visit the GitHub repository: Catching LLMs.
Experiments in comparison to a Manual task
- Experiment 1: to annotate text (binary, 1/0) if a word (+synonym) is present.
- Experiment 2: after following the same steps as experiment 1, for those annotated (1) a sentiment score is to be derived.
- Experiment 3: similar to experiment 1 to annotate text, however this task is to compare a precise objective vs. a broader aim.
Methods
Using Kaggle to access an open source data set, I downloaded a dataset on Spotify user reviews.
This dataset has 51,473 rows, however considering time to manually annotate, I used pandas sample() to filter for a random 100 posts:
df.sample(n=100, random_state=123)
Experiments
Experiment 1 - binary
As mentioned, experiment 1 a binary task to annotate text 1 or 0 if a word is present, also considering synonyms. After a very - quick - initial review, I chose the following words of interest: advertisement, audio, download, and update. I then considered synonyms, plus a quick Google search.
I timed the manual annotation exercise and noted a 1 for each post if the word (and/or synonym) was present. After the manual annotation, some additional synonyms were highlighted:
- Advertisement: ad, advert
- Audio: bluetooth*, quality, sound
- Download: redownload*
- Update: change*, fix*, upgrade**, version
*curated from data; **google.
Experiment 2 - sentiment
Experiment 2 follows similarly to experiment 1, text is checked for a word (and/or synonyms) then a sentiment score is derived for those annotated. In this task, I used “music” as the topic of interest and the following synonyms were included: song, listen*, and track. The main objective in this task is looking at how each method derives a sentiment score: a human’s opinion against LLM interpretation. *curated from data.
Sentiment ranges from -1 (negative) to 0 (neutral) to 1 (positive). Humans can have difficulty scoring sentiment and can be subjective to what is neutral and so with manual annotation I annotated only “p” or “n”. With the computational scores, I can convert them into “p” and “n” via thresholds:
if Score > 0.05 = p (positive)
elif Score < -0.05 = n (negative)
else = neutral
Jabberwocky doesn’t have sentiment analysis included yet and so in this experiment after Catch does the annotation, each annotated post will go through VADER sentiment analysis. It is my goal in the future to implement sentiment analysis into Jabberwocky as a function.
Experiment 3 - broader
In a final experiment, although similar to experiment 1 in terms of annotating text for terms and synonyms, the focus will shift in this experiment to comparing search strategies: each method will conduct two inner tasks relating to paying for the App.
The first is a precise approach to annotate posts relating to App payments, for example Catch is to annotate using only “pay” while LLMs will annotate posts related to paying for the App. The second task is broader: Catch will annotate using various terms alongside “pay” and the LLMs will annotate if the post is related to paying for the App with additional terms.
This experiment covers three methods: manual annotation to highlight posts related to paying for the App; Catch will show the power of additional terms/synonyms for annotation tasks; and LLMs will show the flexibility and differences in approaches for models.
Additional terms/synonyms: buy, cents*, expensive, features, free, invaluable*, money, paid, payment, premium, price, subscribe*.
*curated from data.
Jabberwocky
Jabberwocky’s Catch script includes text cleaning, lemmatisation (putting words in base form), and removes stop words (e.g. we, my, had, isn’t). The code snippet below shows this:
[in] Hello world! This is an example of text cleaning with lemmatisation and stop word removal!
[out] hello world example text clean lemmatisation stop word removal
As you can see, tokens are put in lowercase and special characters (!) are cut. Words like “this, is, an, of, with, and” are stop words and so have been removed. The word “cleaning” has been put into base form as “clean” (lemmatisation).
LLMs
Using GroqCloud API I chose 3 models. The Table below highlights the models used; the column, “Referred as” is how these models will be mentioned throughout this article.
| Model | Developer | Referred as |
|---|---|---|
gemma2-9b-it | Gemma | |
llama-3.1-8b-instant | Meta | Llama |
mixtral-8x7b-32768 | Mistral | Mixtral |
Table: The models used in this experiment.
Statistics
In this final section, I have introduced the various statistical tests I conduct throughout the experiments.
| Experiment 1 |
|---|
| Accuracy: how often the method predicted the manual 1s and 0s. For example, 0.97 means the method correctly identified 97 out of every 100 cases. |
| Cohen’s Kappa: measures how well the method agrees with the manual annotation, highlighting performance if meaningful or randomness. For example, a score of 0.8 means a strong agreement. An agreement score was also derived via a threshold. |
| Matthews Correlation Coefficient: measure of the method’s performance considering all correct and incorrect predictions. For example, 0.86 indicates the method is performing well and a strong positive correlation. It is useful with uneven distributions of 1s and 0s. |
| Precision: how accurate the predicted 1s are. For example, 0.77 means 77% of the time the method correctly predicted 1. |
| Recall (also called sensitivity): measures how good the method is at identifying actual 1s and not missing any. For example, 1 (or 100%) means the method correctly predicted all the “1” cases. |
| F1-score: the balance between precision and recall. For example, 0.87 means the method strikes a pretty good balance between catching all 1s (recall) AND ensuring 1s are accurate (precision). Useful with uneven distributions of 1s and 0s. |
| Experiment 2 |
|---|
| Converting scores into ints, I curated: Accuracy, Kappa, and Correlation. |
| For the continuous scores, I conducted a T-statistic: the difference between two methods via the averages, considering variability. A larger T-statistic (from 0) suggests a greater difference. |
| Experiment 3 |
|---|
| McNemar: measures the size of change of two related techniques, e.g. precise vs. broad. A higher McNemar value represents the number of discordant pairs (changes between conditions). |
| Friedman: check for significant differences in related groups, e.g. differences in all broad methods. Larger values indicate a greater difference between groups (one method may perform noticeably better/worse than others). |
Most importantly, P-values were calculated. A P-value represents the randomness of the statistical test. A small P-value indicates significance, meaning the test is unlikely to be random. P-value size is often discussed/disputed as to define what is significant, often we see p<0.05 is the limit for significance.
Results
Of the Spotify review data set, after filtering by a random sample of n=100 the average word count is 26.54 per post/review/row.
Experiment 1 - binary
The code snippet below shows the request to the LLM:
The following sentence is a review of an App.
Print a 1 or 0 if any of the following words [list_of_words] are mentioned.
Your response should only have the necessary data of a 1 or 0. Sentence: ...
Timings
| Method | Total (minutes) | Average per word (+synonyms) |
|---|---|---|
| Manual | 19.3 | 4.8 |
| Catch | 0.06 | 0.01 |
| LLMs | 11.68 | 2.92 |
Table: Time to annotate the 100 posts for each method and the average for each word of interest.
Counts
| Method | Advertisement | Audio | Download | Update |
|---|---|---|---|---|
| Manual | 10 | 4 | 6 | 14 |
| Catch | 9 | 6 | 6 | 25 |
| Gemma | 13 | 7 | 7 | 22 |
| Llama | 8 | 0 | 1 | 15 |
| Mixtral | 8 | 8 | 7 | 22 |
Table: Sum of 1s for each method for each word of interest (+synonyms).
Within each word of interest, while I did compare each method to the “gold standard” manual annotation, I also compared methods against each other via a pairwise Cohen’s Kappa. Within each word of interest, Catch and Gemma had strong agreements (advertisement=0.8, audio/download/update=0.92).
Terms of interest
Advertisement + ad, advert.
For this word of interest, all methods had an accuracy of at least 90% - see the Table below. Both Catch and Gemma had the strongest agreements, with Catch having better results (higher F1-score) across tests and an almost perfect (94%) Kappa agreement.
| Method | Accuracy | Kappa | Agreement | Correlation | Precision | Recall | F1-score |
|---|---|---|---|---|---|---|---|
| catch | 0.99 | 0.94 | Almost perfect | 0.94 | 1 | 0.9 | 0.95 |
| gemma2 | 0.97 | 0.85 | Strong | 0.86 | 0.77 | 1 | 0.87 |
| llama | 0.94 | 0.63 | Moderate | 0.64 | 0.75 | 0.6 | 0.67 |
| mixtral | 0.94 | 0.63 | Moderate | 0.64 | 0.75 | 0.6 | 0.67 |
Table: Statistical tests on each method when compared to manual annotation for “advertisement”.
Catch didn’t pick up a post which had misspelling “adds” but Gemma did. Gemma also annotated posts with “adv” that were most likely “adverts” so in this instance an LLM picked up something a human missed.
Both Llama and Mixtral also picked up some “adv” and “adds” posts. There were posts Llama and Mixtral missed due to it being “ads” in the text (plural), which Catch can handle via lemmatisation.
| A | B | C |
|---|---|---|
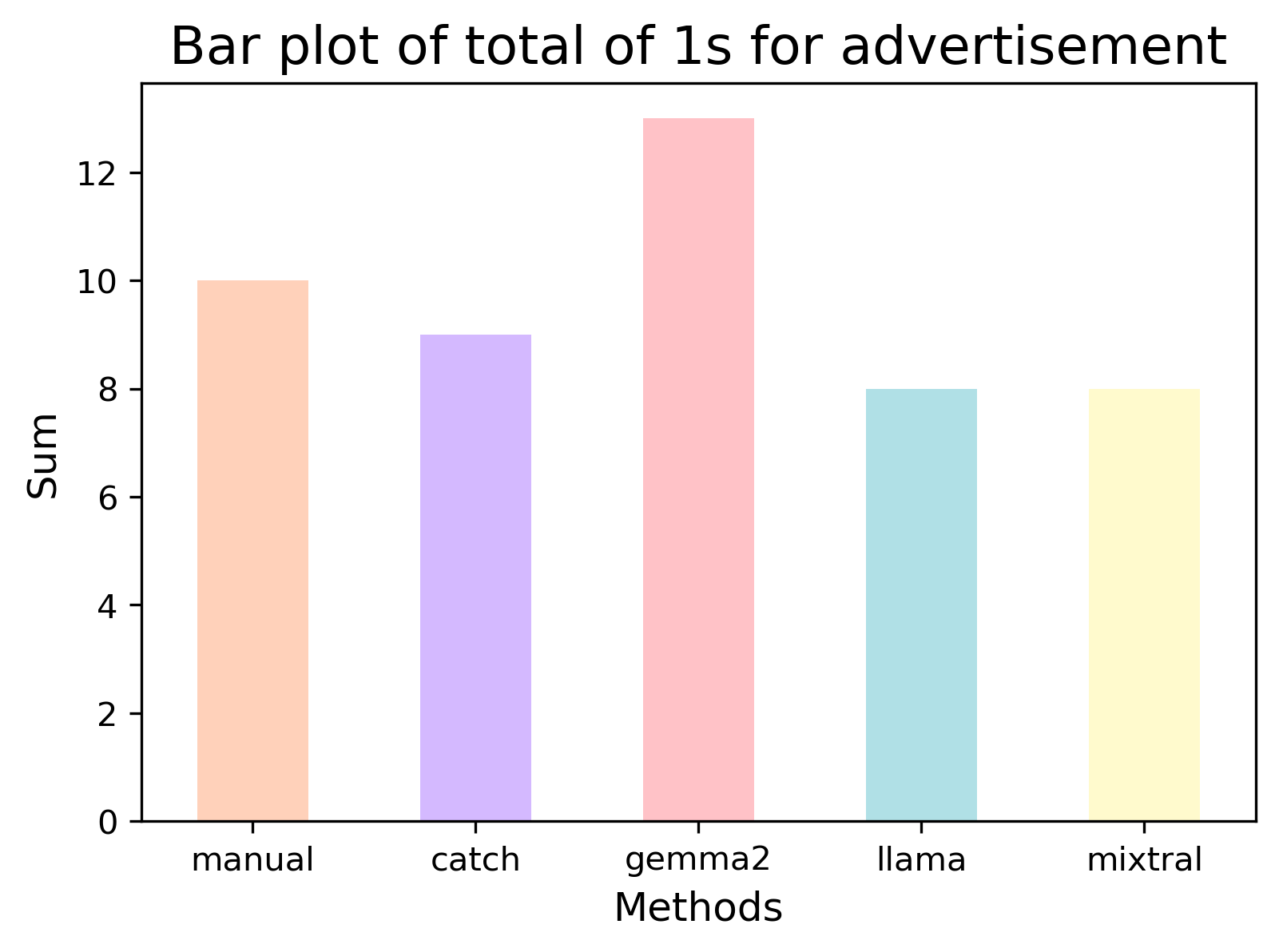 |  | 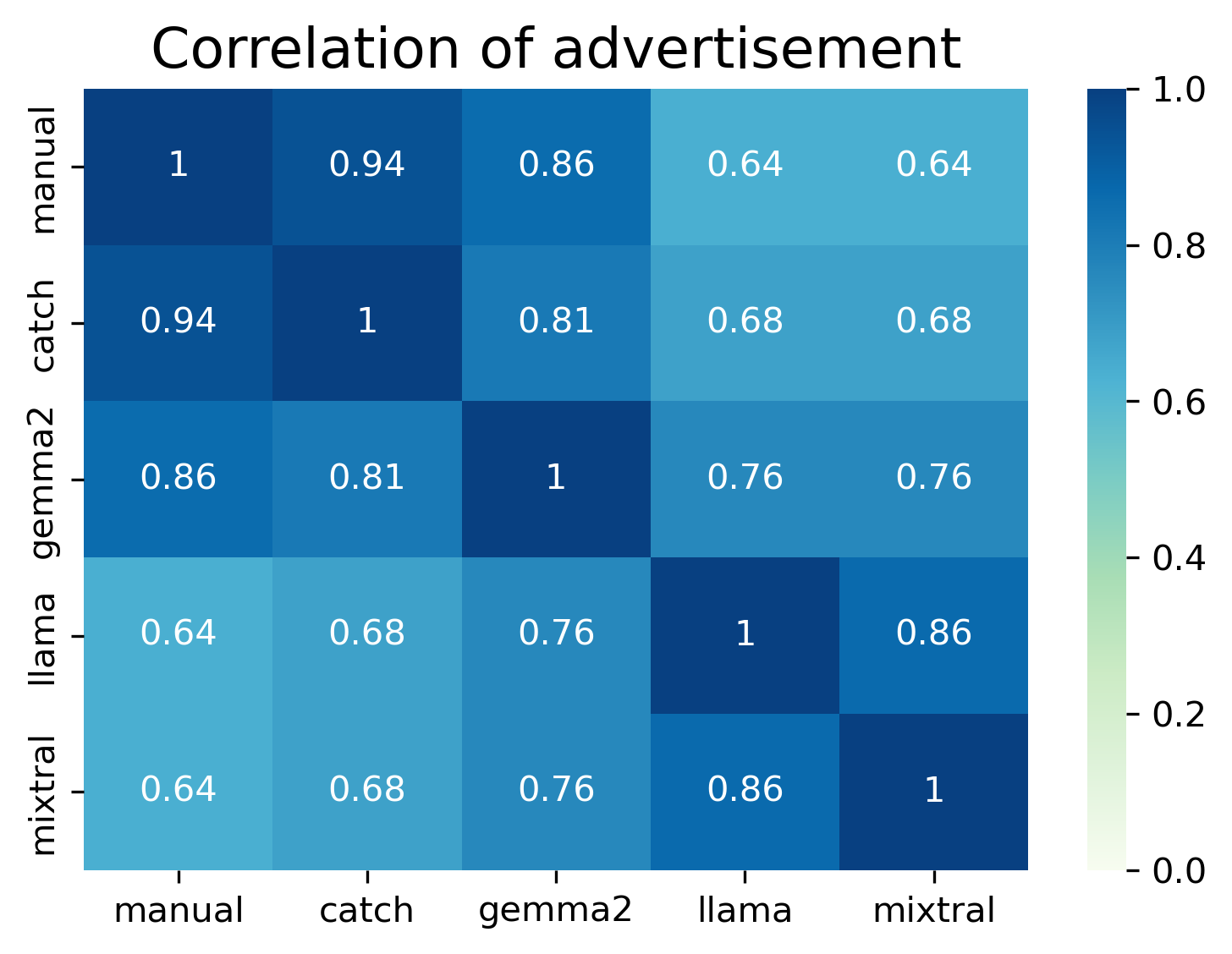 |
Figure: Plots to visualise the results for “advertisement”.
Audio + bluetooth, quality, sound.
In “audio” we see interestingly that Llama didn’t annotate anything (below) and with some investigation, Llama simply returned a 0 for all. Of the other methods, both Catch and Gemma again had higher accuracies but no model had a particularly strong agreement with the manual annotation - see below.
| Method | Accuracy | Kappa | Agreement | Correlation | Precision | Recall | F1-score |
|---|---|---|---|---|---|---|---|
| catch | 0.98 | 0.79 | Moderate | 0.81 | 0.67 | 1 | 0.8 |
| gemma2 | 0.97 | 0.71 | Moderate | 0.74 | 0.57 | 1 | 0.73 |
| llama | 0.96 | 0 | None | 0 | 0 | 0 | 0 |
| mixtral | 0.94 | 0.47 | Weak | 0.5 | 0.38 | 0.75 | 0.5 |
Table: Statistical tests on each method when compared to manual annotation for “audio”.
Both Catch and Gemma picked up two additional posts, one I missed, another specific to functionality of the app (play/pause) which is correctly annotated however in terms of context I didn’t annotate this. Mixtral annotated posts that neither I, Catch, or Gemma annotated. These posts included words like “listen”.
| A | B | C |
|---|---|---|
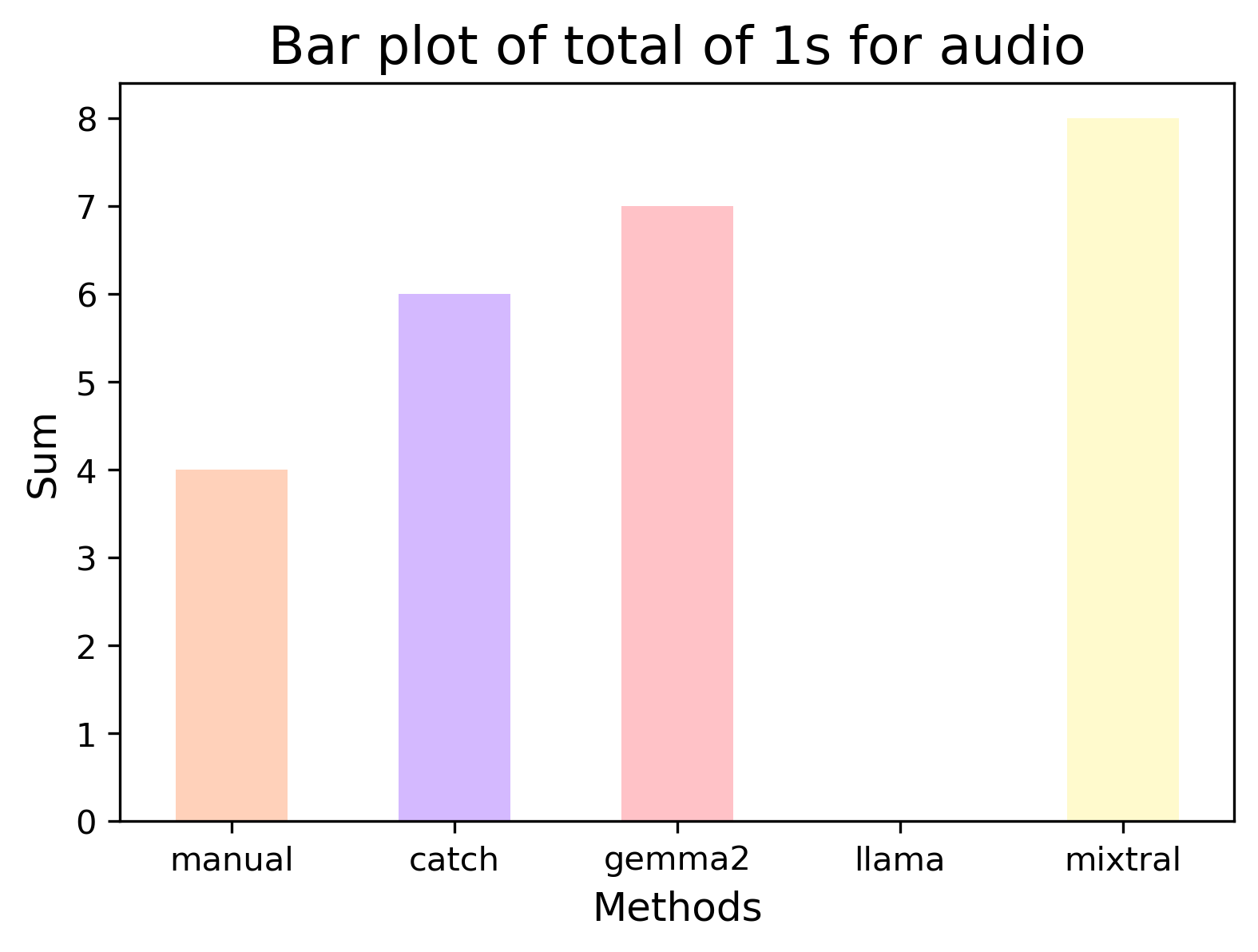 | 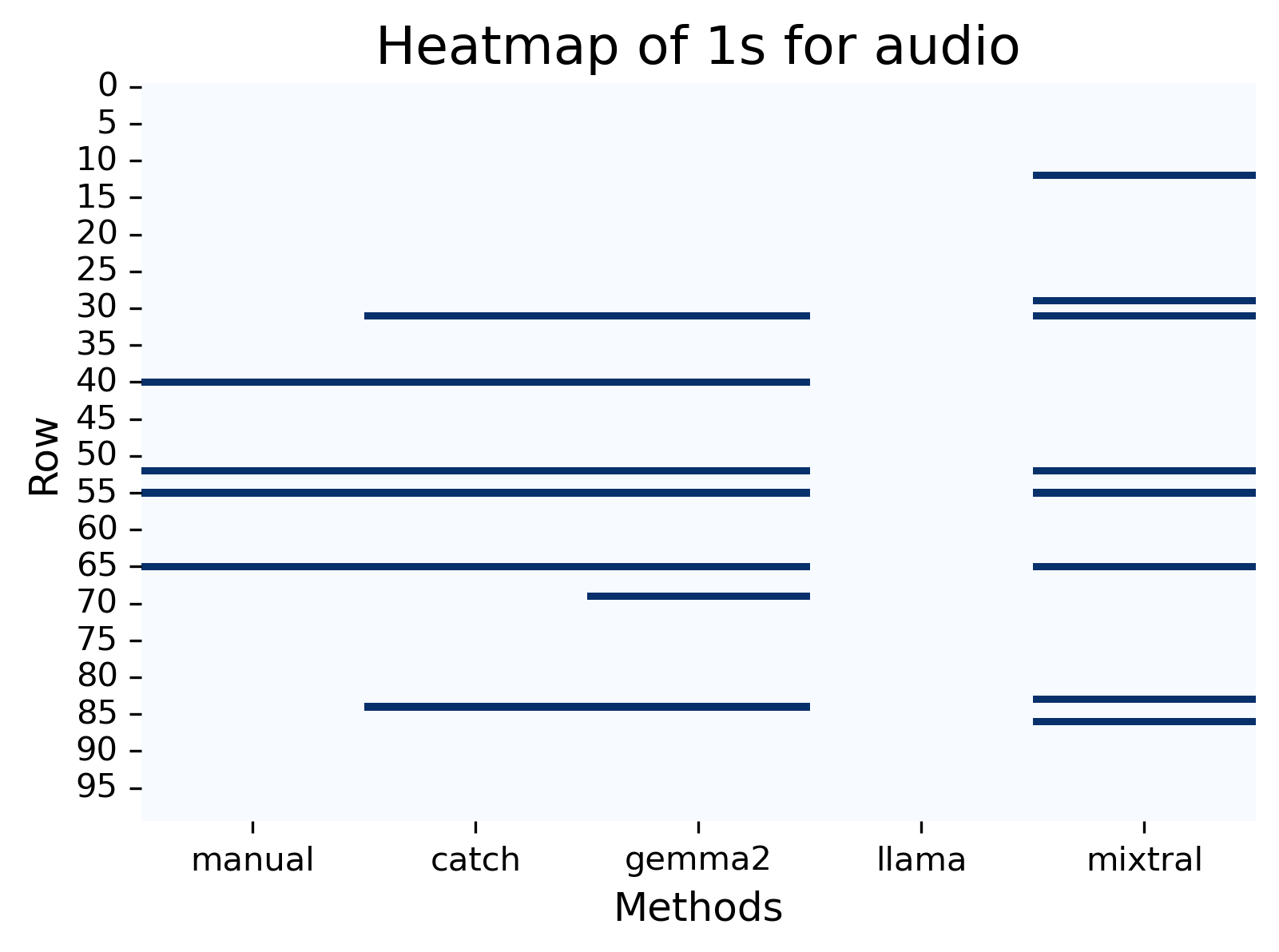 | 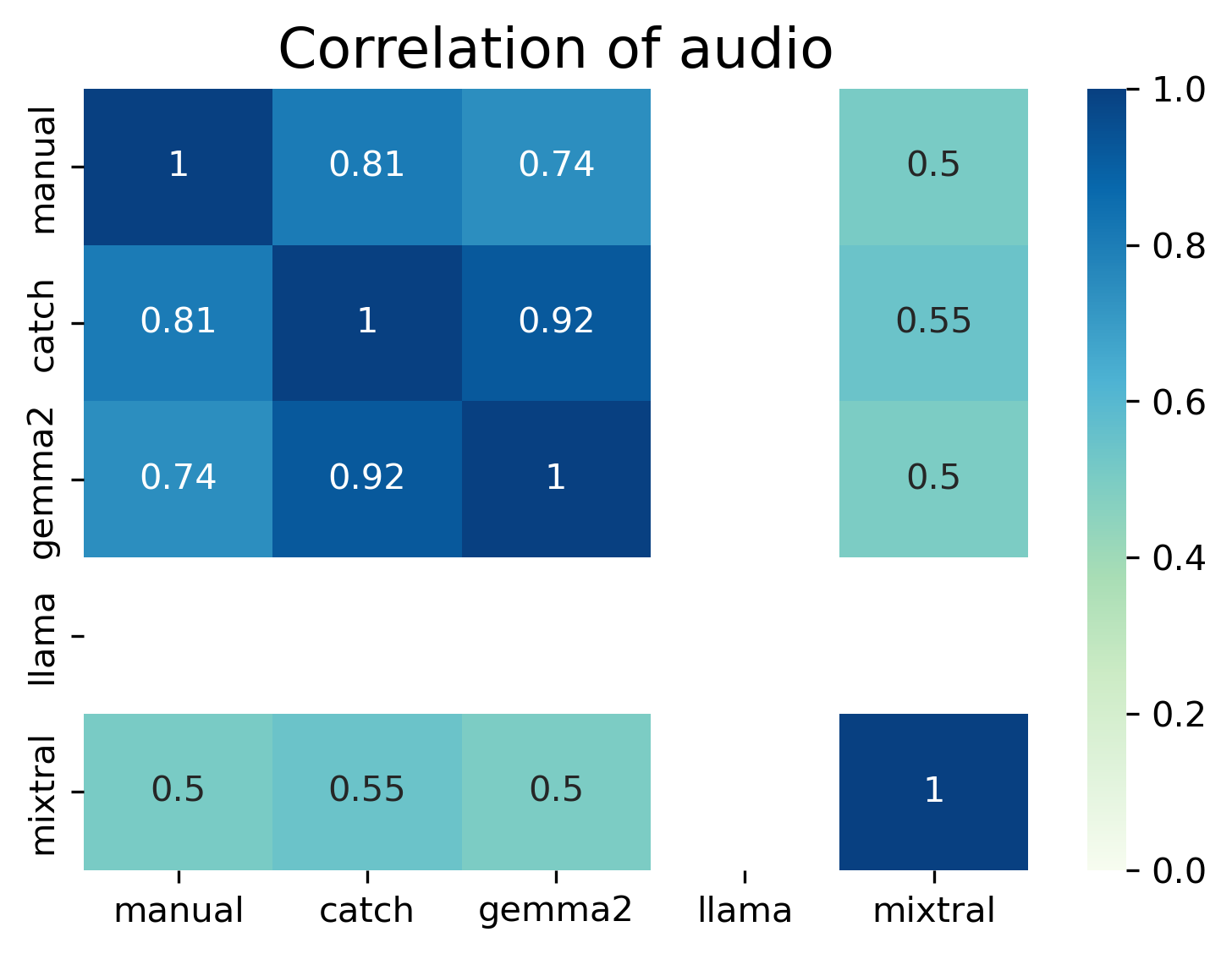 |
Figure: Plots to visualise the results for “audio”.
Download + redownload.
In the Table below, for “download” we see an accuracy of higher than 90% for all methods with Catch having 100% and Gemma 99% also reflecting Catch and Gemma’s Kappa agreement, correlation, and F1-score. However, despite the high accuracy, both Llama and Mixtral other results weren’t as strong.
| Method | Accuracy | Kappa | Agreement | Correlation | Precision | Recall | F1-score |
|---|---|---|---|---|---|---|---|
| catch | 1 | 1 | Perfect | 1 | 1 | 1 | 1 |
| gemma2 | 0.99 | 0.92 | Almost perfect | 0.92 | 0.86 | 1 | 0.92 |
| llama | 0.95 | 0.27 | Minimal | 0.4 | 1 | 0.17 | 0.29 |
| mixtral | 0.95 | 0.59 | Weak | 0.59 | 0.57 | 0.67 | 0.62 |
Table: Statistical tests on each method when compared to manual annotation for “download”.
Catch picked up the exact number of posts that I manually annotated. Gemma annotated an additional post which when reviewing I do not believe is related to downloading. Llama missed all posts with “downloaded” (past tense). Mixtral annotated a post which I believe was annotated due to words: “reinstall” and/or “streaming”.
| A | B | C |
|---|---|---|
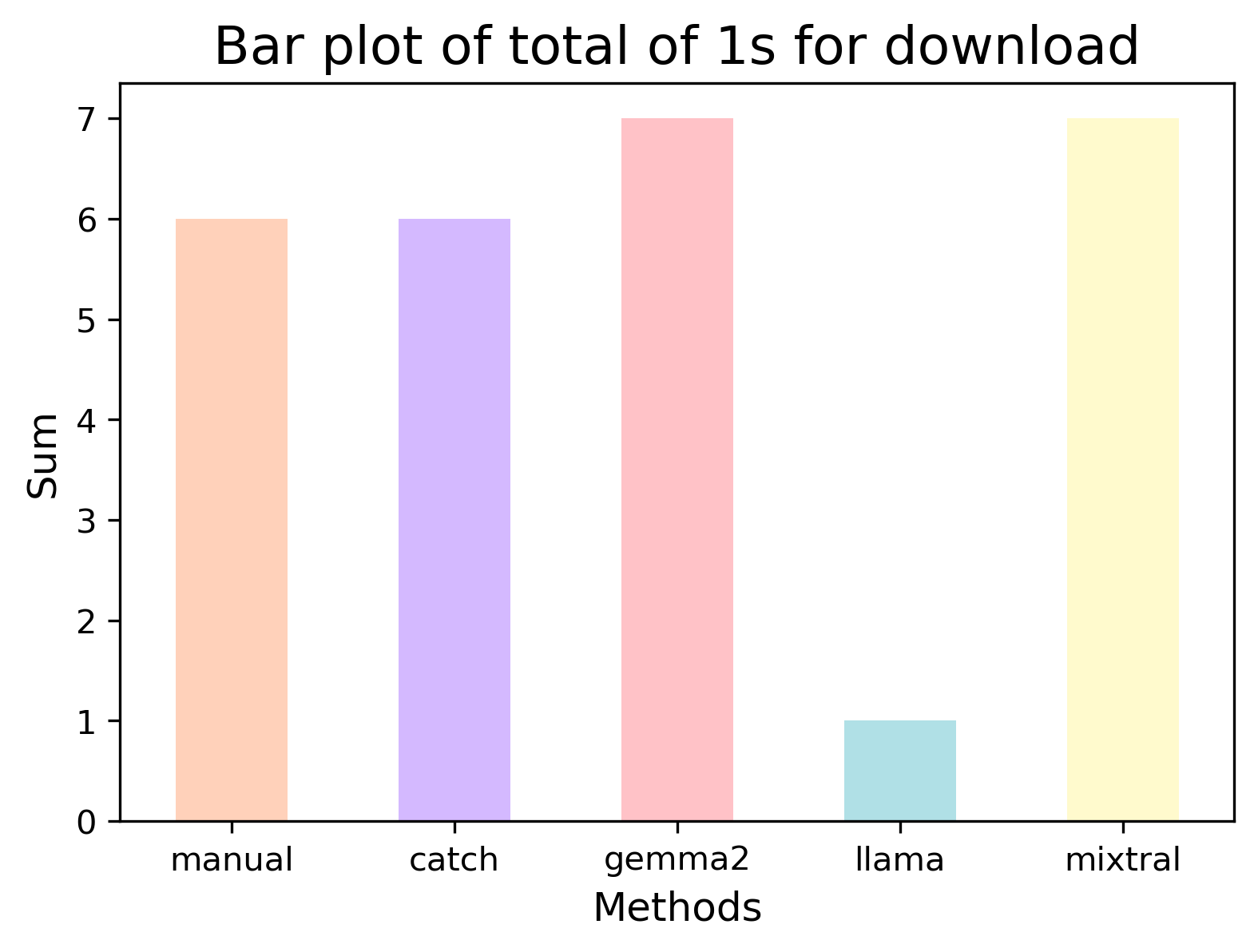 | 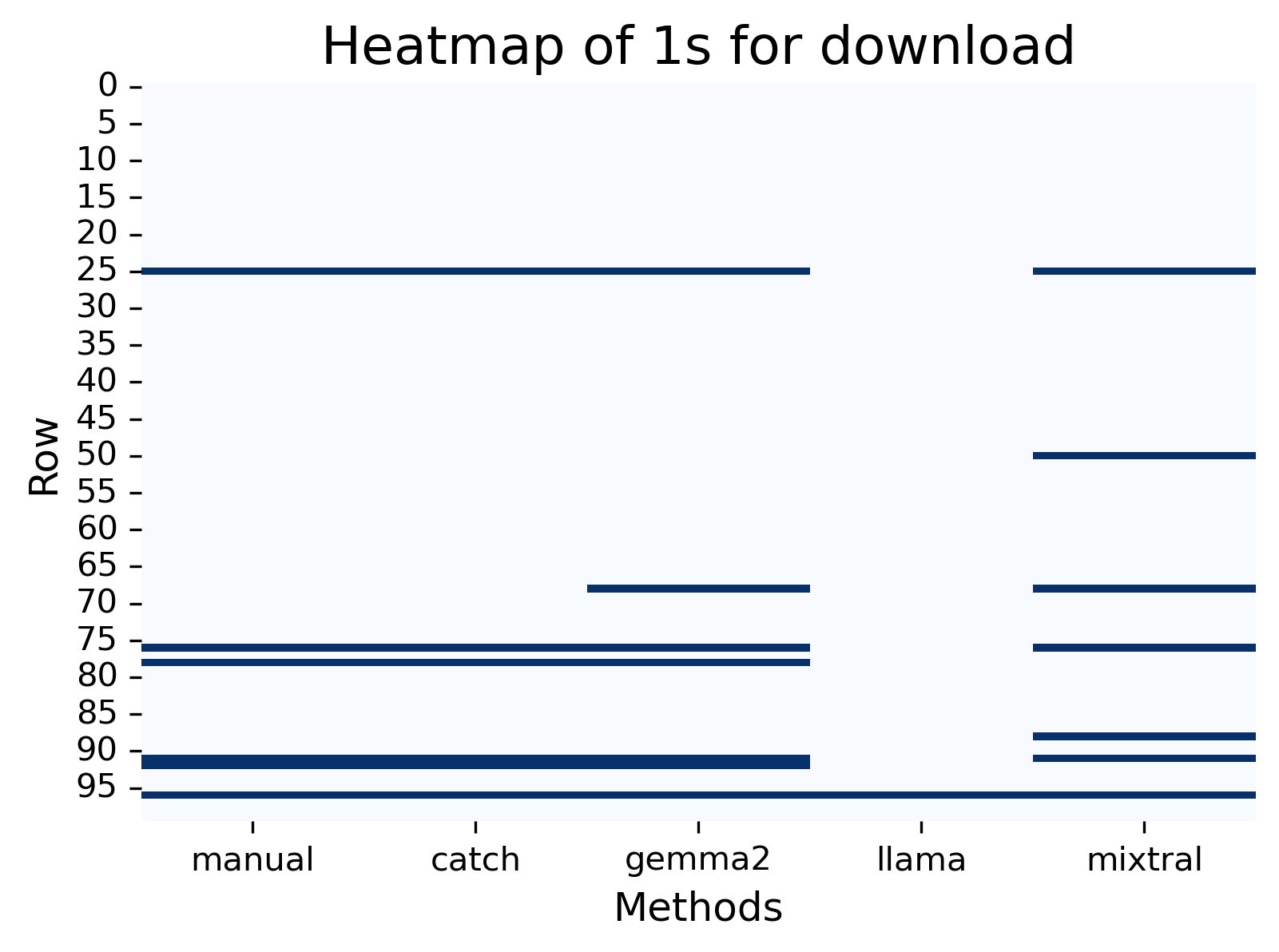 | 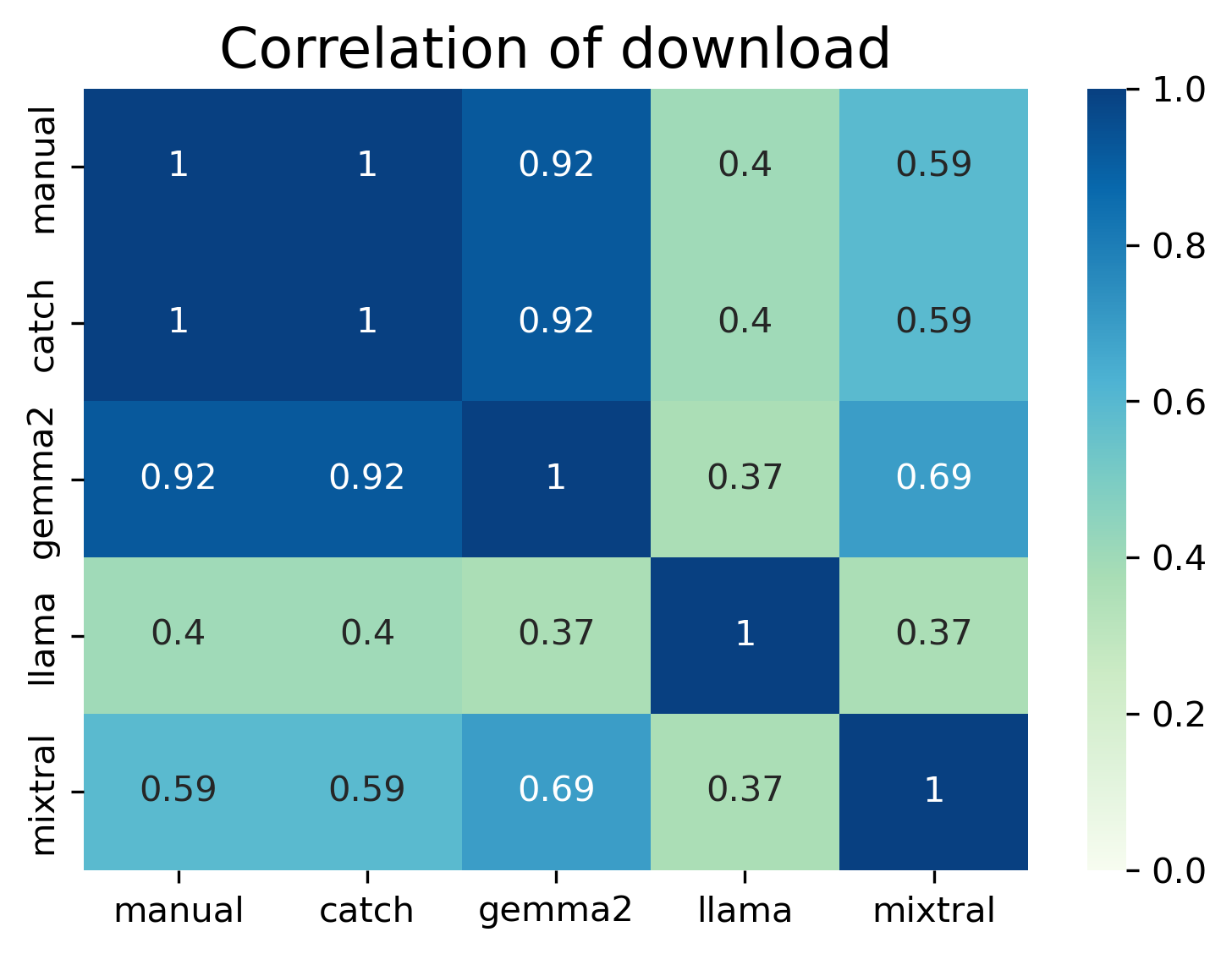 |
Figure: Plots to visualise the results for “download”.
Update + change, fix, upgrade, version.
Finally, in this final word of interest, there are accuracy scores of almost 90% and higher. The F1-score for Catch was 0.72, Gemma 0.78, Llama 0.83, and Mixtral 0.78 - all similar Kappa and correlations. Llama had a stronger agreement in this test, perhaps due to more synonyms.
| Method | Accuracy | Kappa | Agreement | Correlation | Precision | Recall | F1-score |
|---|---|---|---|---|---|---|---|
| catch | 0.89 | 0.66 | Moderate | 0.7 | 0.56 | 1 | 0.72 |
| gemma2 | 0.92 | 0.73 | Moderate | 0.76 | 0.64 | 1 | 0.78 |
| llama | 0.95 | 0.8 | Strong | 0.8 | 0.8 | 0.86 | 0.83 |
| mixtral | 0.92 | 0.73 | Moderate | 0.76 | 0.64 | 1 | 0.78 |
Table: Statistical tests on each method when compared to manual annotation for “update”.
All methods picked up additional posts based on the synonyms, and LLMs annotated posts that were out of context, for example posts about the App’s “free version” or “upgraded to [new phone model]”. Gemma missed a post with “version” in the text and Mixtral had similar results to Gemma. Llama did not annotate a post with “change” regarding “change the app”.
| A | B | C |
|---|---|---|
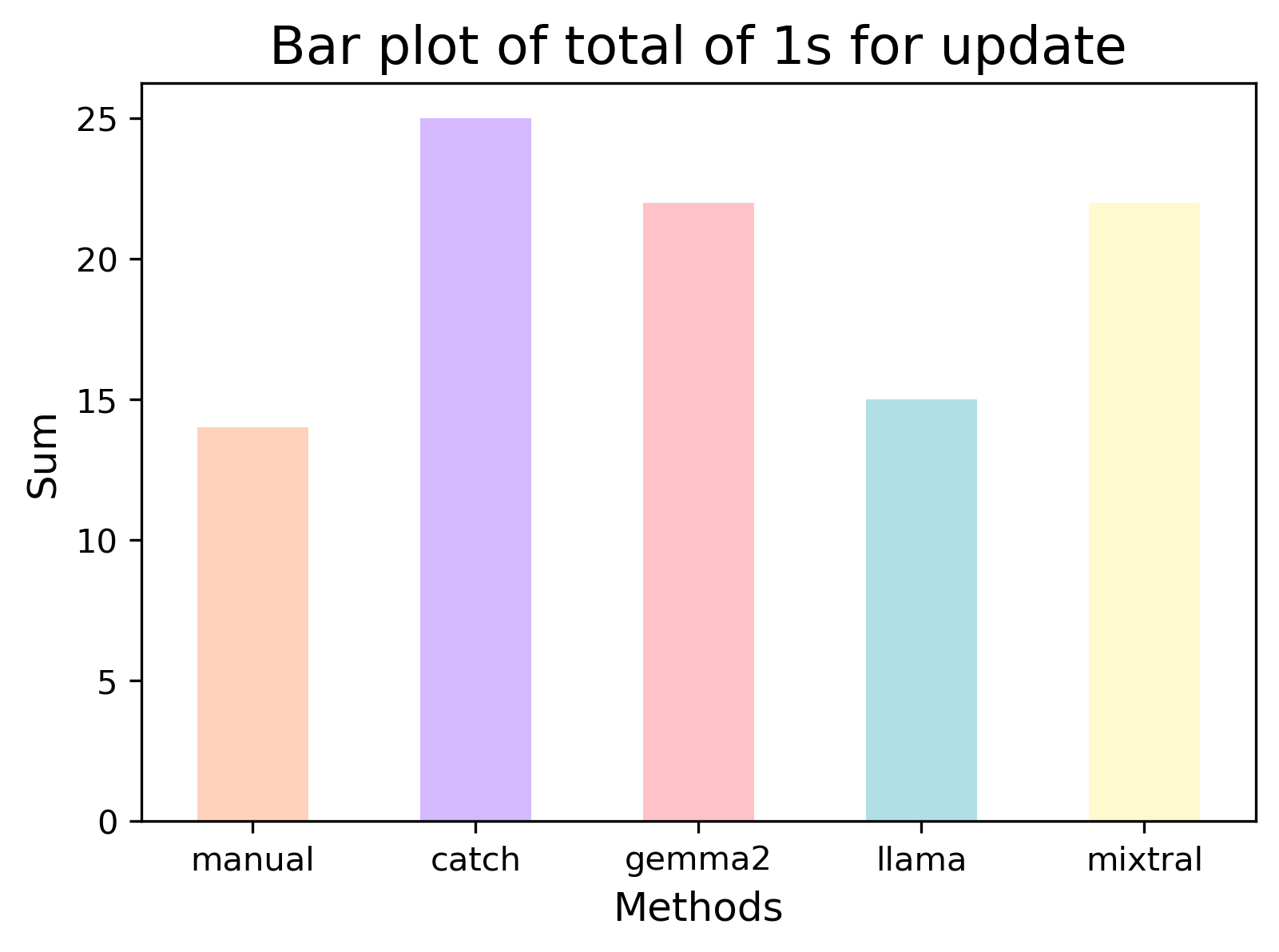 | 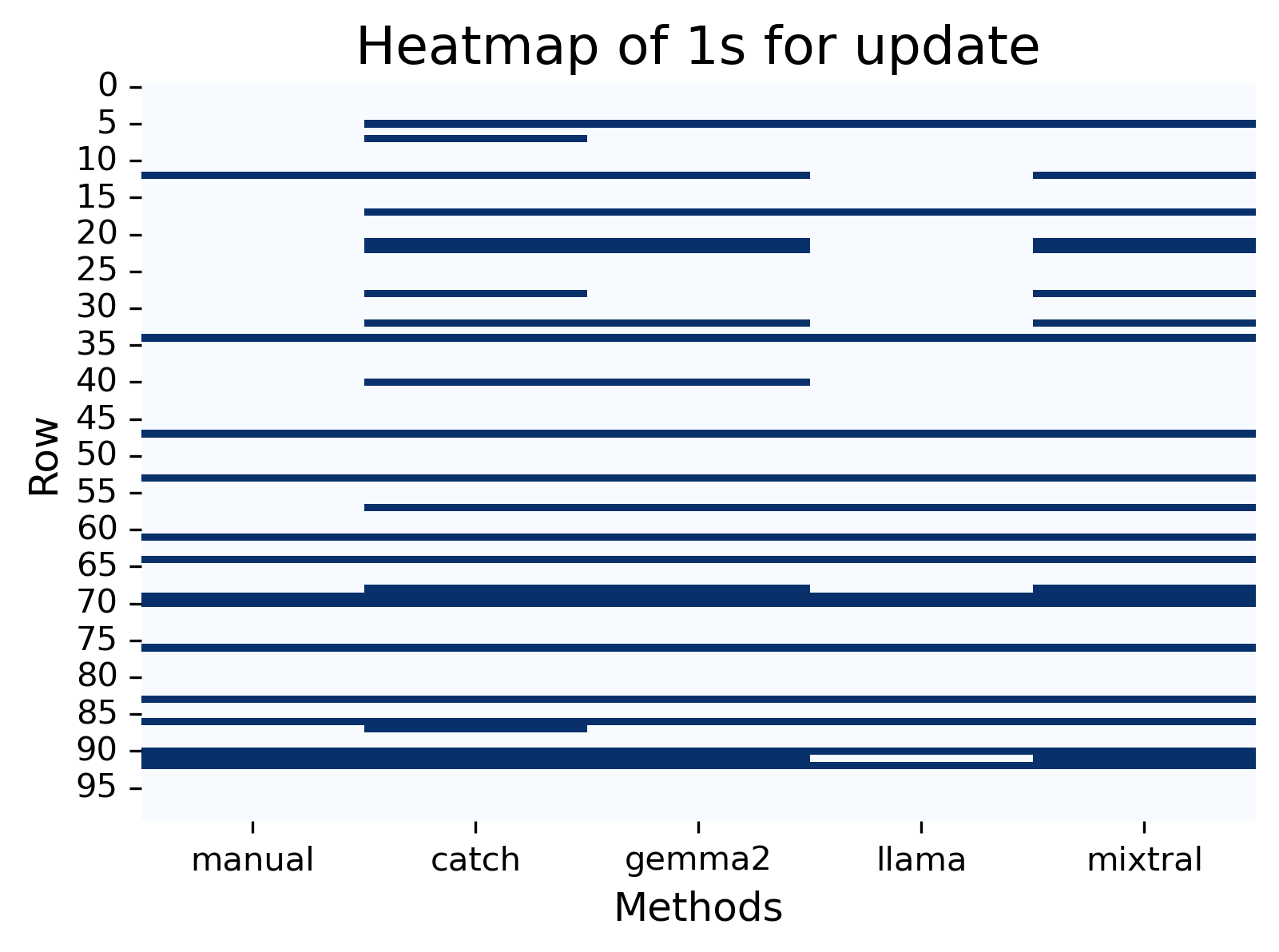 | 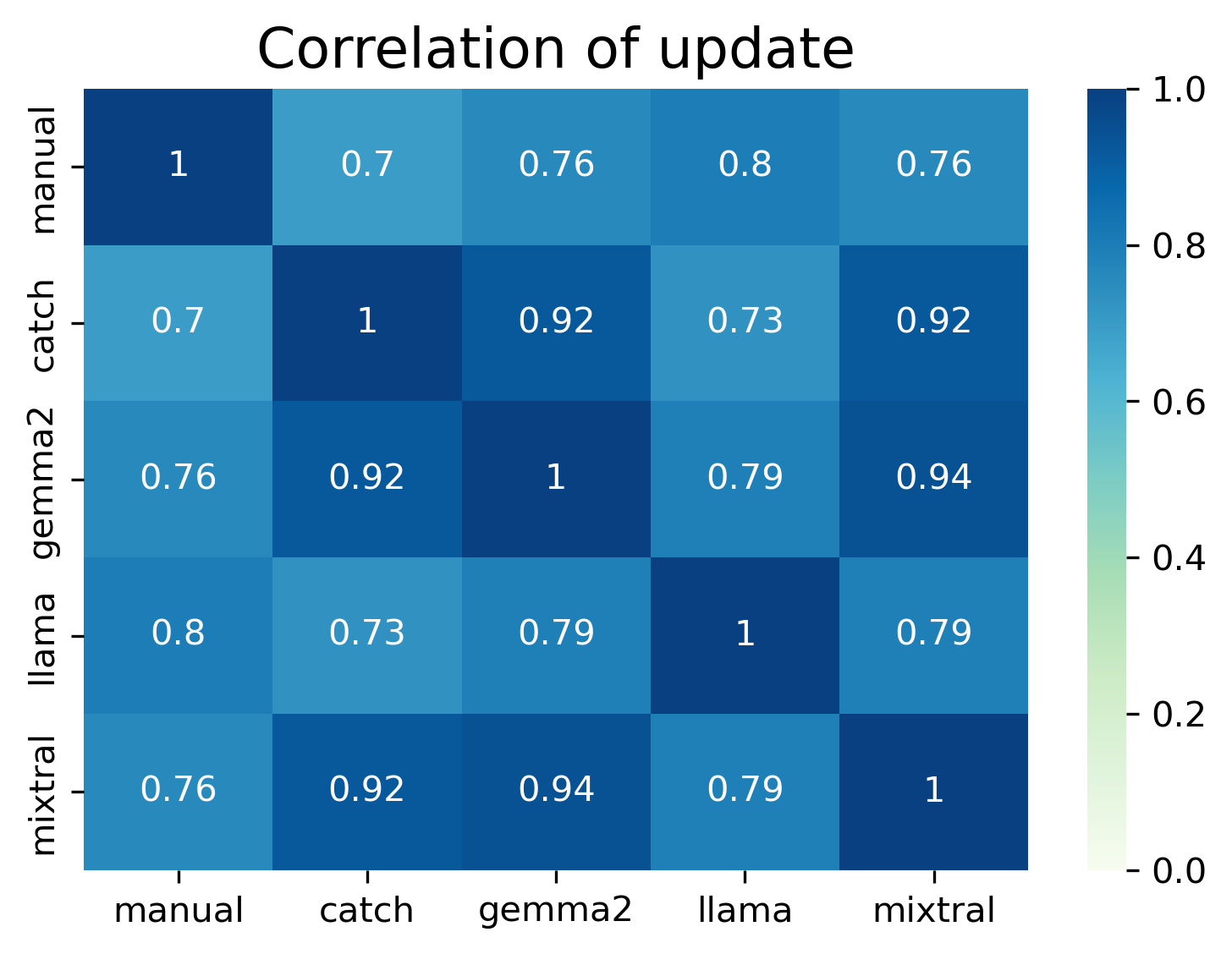 |
Figure: Plots to visualise the results for “update”.
Experiment 2 - sentiment
music + song, listen, and track.
The code snippet below shows the request to the LLM:
The following sentence is a review of an App.
Print a sentiment score between -1 (negative) to 0 (neutral) to 1 (positive).
You should ONLY PRINT a score if any of the following words [list_of_words] are mentioned in the sentence - do not bother with the sentence if a word of interest is not present.
Your response should only have the necessary data of a sentiment score (return ONLY a -10 if a word of interest is not present).
Sentence: ...
Timings
| Method | Total (minutes) |
|---|---|
| Manual | 7.44 |
| Catch (+VADER) | 0.02 |
| LLMs | 3.06 |
Table: Time to annotate the 100 posts for each method and provide a sentiment score.
Counts
| Method | Positive | Negative | Neutral | Annotated | Not annotated | |
|---|---|---|---|---|---|---|
| Manual | 28 | 30 | 58 | 42 | ||
| Catch (+VADER) | 41 | 14 | 4 | 66 | 41 | |
| Gemma | 39 | 26 | 5 | 70 | 30 | |
| Llama | 36 | 13 | 2 | 51 | 49 | |
| Mixtral | 41 | 37 | 78 | 22 |
Table: Sum of sentiment responses for each method, with total annotated and not annotated counts.
Sentiment
As we see below, the accuracies range from 75 to 80% and p-values are small with the exception of Llama, meaning Llama’s differences are random whereas the other methods are doing something different.
| Method | Accuracy | Kappa | Agreement | Correlation | T-statistic | P-value |
|---|---|---|---|---|---|---|
| catch (+VADER) | 0.79 | 0.69 | Moderate | 0.71 | -2.94 | p<0.01 |
| gemma2 | 0.77 | 0.67 | Moderate | 0.68 | -4.08 | p<0.0001 |
| llama | 0.8 | 0.69 | Moderate | 0.72 | 1.56 | p=0.12 |
| mixtral | 0.75 | 0.63 | Moderate | 0.66 | -4.98 | p<0.0001 |
Table: Statistical tests on each method when compared to manual annotation.
With some investigation of differences, in one post that I annotated positive (a user mentioning how Spotify has all the classical music they want), other models annotated positive with the exception of VADER which annotated as neutral. In retrospect, I can understand this decision. In one post, I accidentally annotated as positive, and so did Llama, however VADER, Gemma, and Mixtral annotated correctly as negative. Another post, regarding giving a one star review, VADER noted as neutral, Gemma as positive, and Llama and Mixtral as negative (correct). Finally, one post that was negative: VADER and Llama annotated as positive whilst correctly Gemma and Mixtral as negative.
| A | B | C |
|---|---|---|
 | 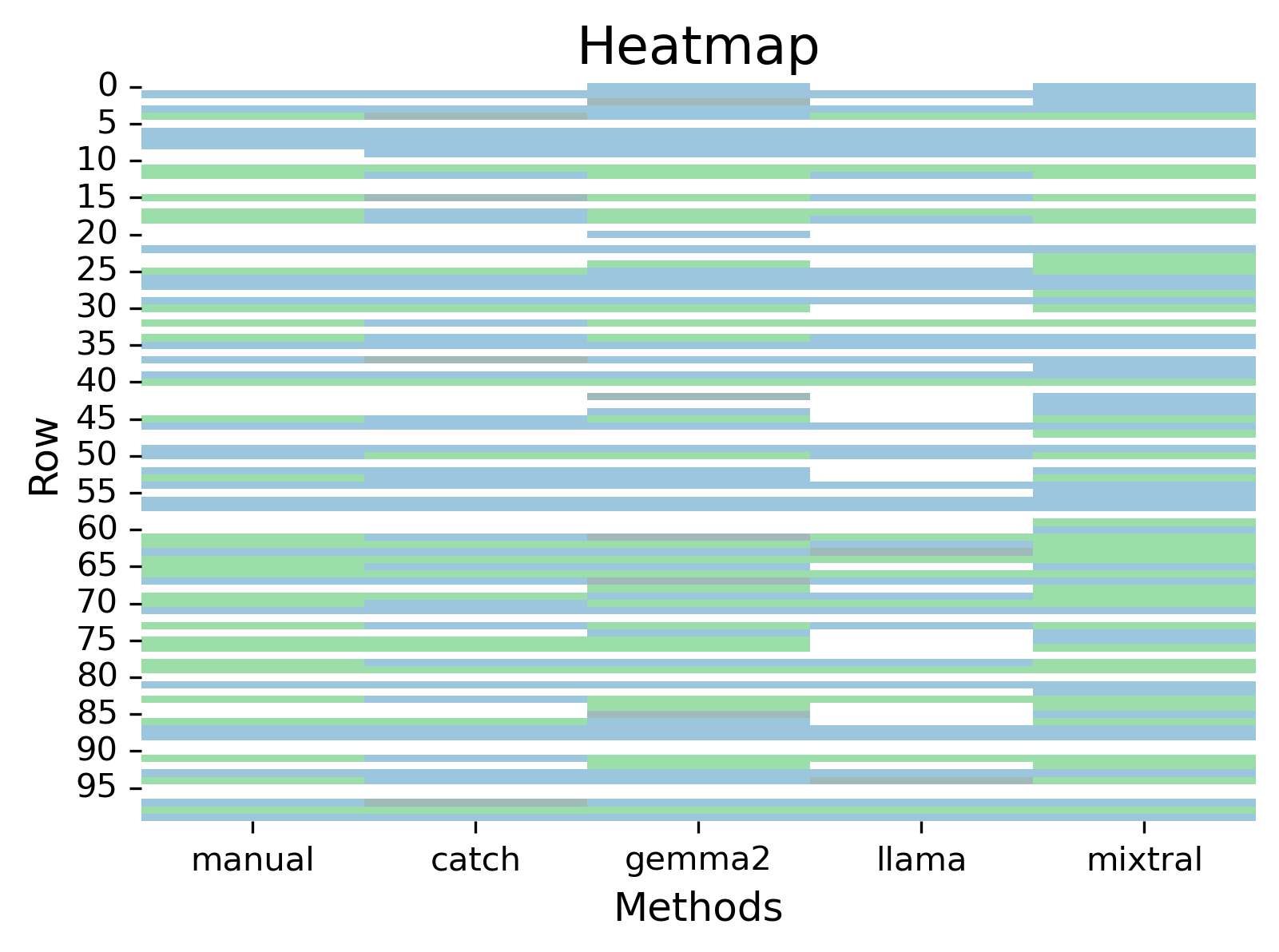 | 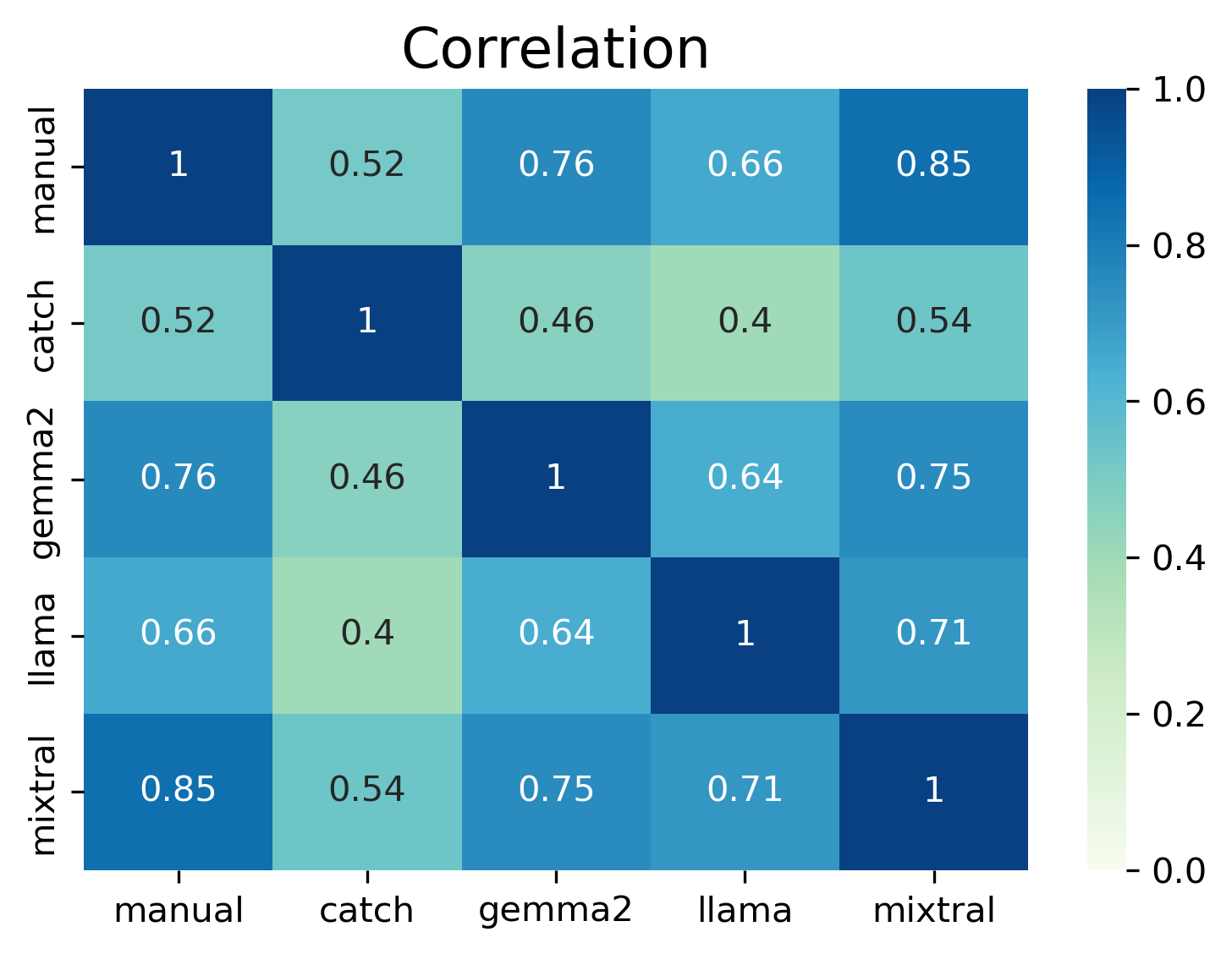 |
Figure: Plots to visualise the results for the sentiment analysis.
If we consider only those annotated in the manual annotation n=58 in Table N, we see Gemma and Mixtral have better accuracy scores, with Mixtral having the strongest Kappa agreement, yet we lost the p-value significance for Mixtral and gain for Llama.
| Method | Accuracy | Kappa | Agreement | Correlation | T-statistic | P-value |
|---|---|---|---|---|---|---|
| catch (+VADER) | 0.66 | 0.36 | Minimal | 0.41 | -3.76 | p<0.001 |
| gemma2 | 0.81 | 0.64 | Moderate | 0.66 | -2.36 | p<0.05 |
| llama | 0.67 | 0.45 | Weak | 0.5 | 2.14 | p<0.05 |
| mixtral | 0.91 | 0.83 | Strong | 0.83 | -0.44 | p=0.66 |
Table: Statistical tests on each method when compared to manual annotation after dropping rows/posts that weren’t related to music in the manual annotation.
Experiment 3 - broader
pay + buy, cents, expensive, features, free, invaluable, money, paid, payment, premium, price, subscribe.
The code snippet below shows the request to the LLM:
if r == "precise":
The following sentence is a review of an App.
Print a 1 or 0 if the sentence is related to paying for the app.
Your response should only have the necessary data of a 1 or 0. Sentence: ...
elif r == "broad":
The following sentence is a review of an App.
Print a 1 or 0 if the sentence is related to any of these words [list_of_words].
Your response should only have the necessary data of a 1 or 0. Sentence: ...
Timings
| Method | Total (minutes) |
|---|---|
| Manual | 6.11 |
| Catch (precise) | 0.01 |
| Catch (broad) | 0.01 |
| LLMs | 2.99 |
Table: Time to annotate the 100 posts for each method on average.
Counts
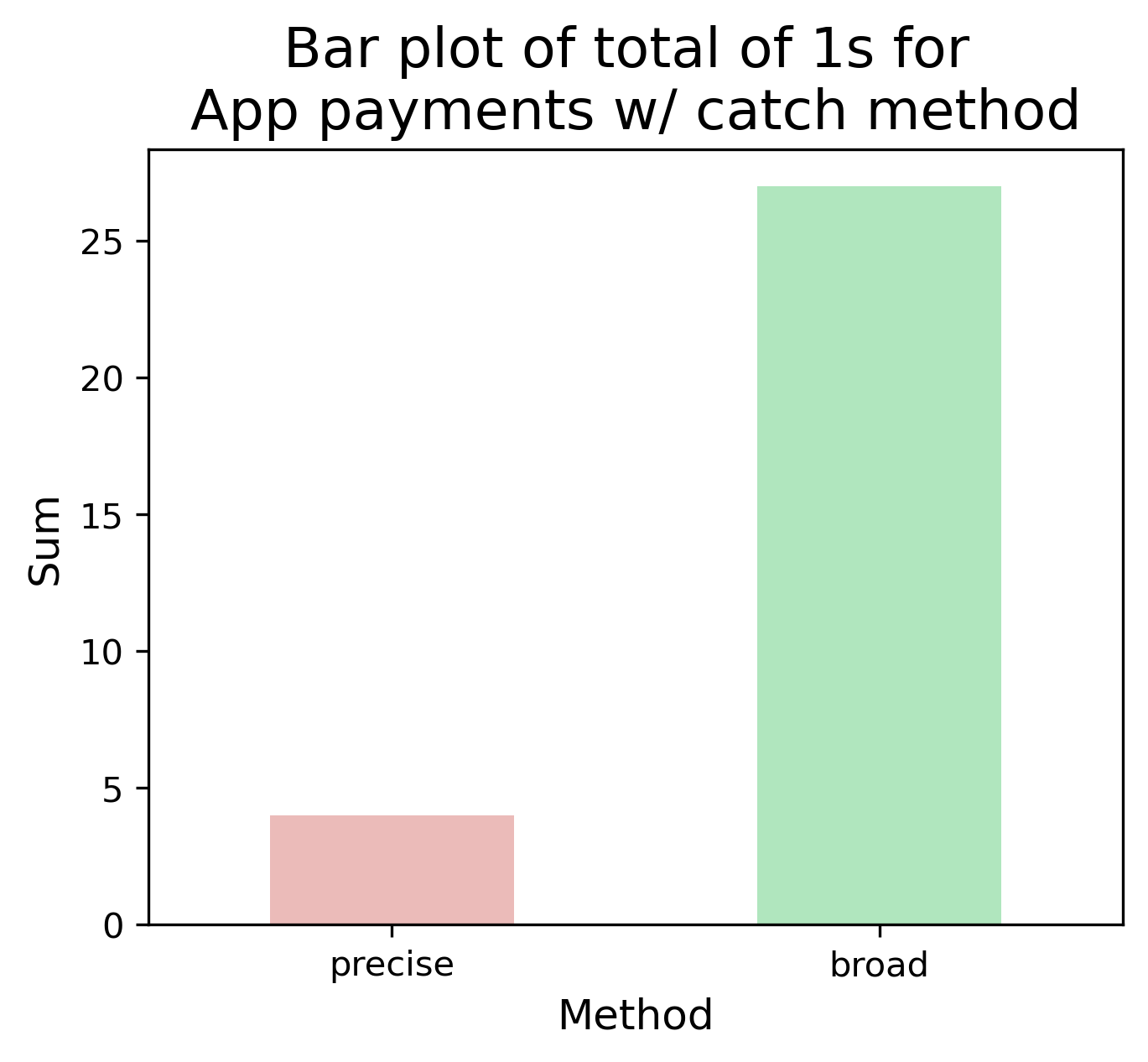
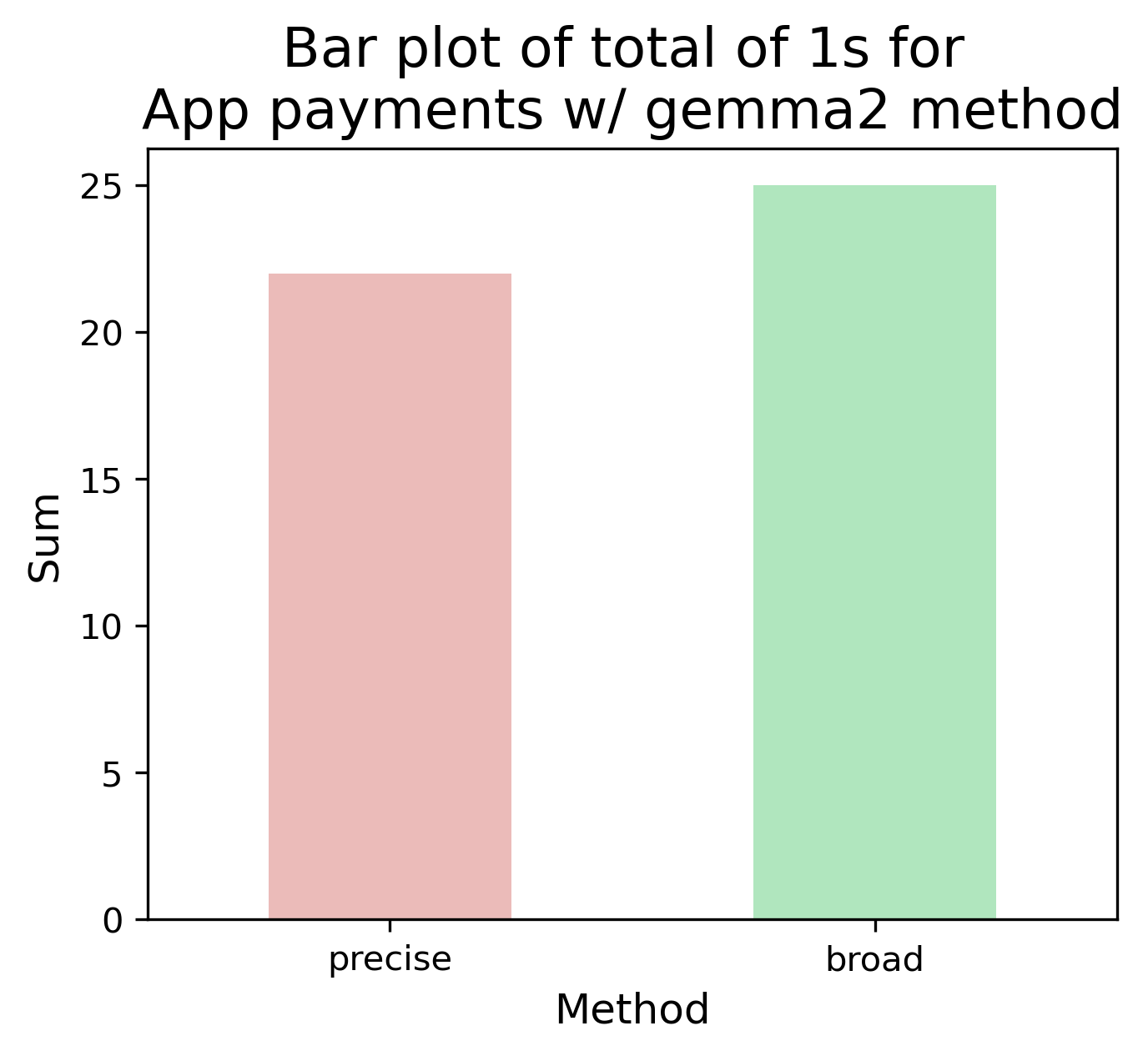
| Method | Count (precise) | Count (broad) |
|---|---|---|
| manual | 22 | 22 |
| catch | 4 | 27 |
| gemma2 | 22 | 25 |
| llama | 7 | 18 |
| mixtral | 22 | 29 |
Table: Sum of 1s for each method and within each inner task. Side note: the manual annotation was only performed once.
In the “precise” task (above), Catch and Llama didn’t annotate many posts, whereas Gemma and Mixtral had a large overlap with the manual annotation. However in “broad” when provided more terms, the count increased for all methods - but was this significant?
Precise vs. Broad
From the McNemar P-values, Gemma and Mixtral are not significant, meaning the additional terms/synonyms did not significantly improve the results, from further investigation, the precise results covered the majority of the broader search for these two methods.
| Method | McNemar | P-value |
|---|---|---|
| catch | 0 | p<0.0001 |
| gemma2 | 1 | p=0.375 |
| llama | 0 | p<0.001 |
| mixtral | 3 | p=0.092 |
Table: Statistical tests on each method looking at the power of providing more terms.
| A | B |
|---|---|
 |  |
| C | D |
|---|---|
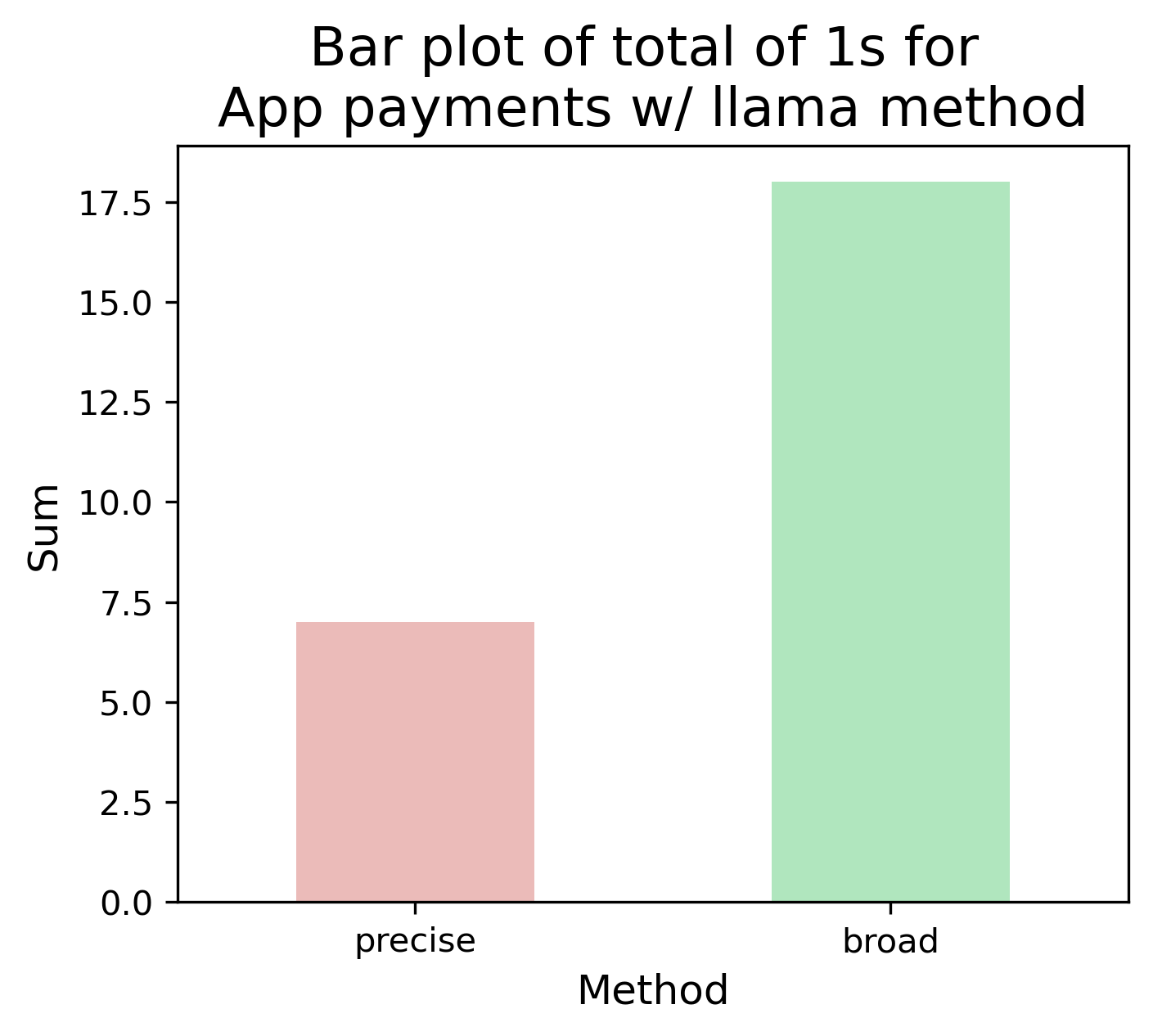 | 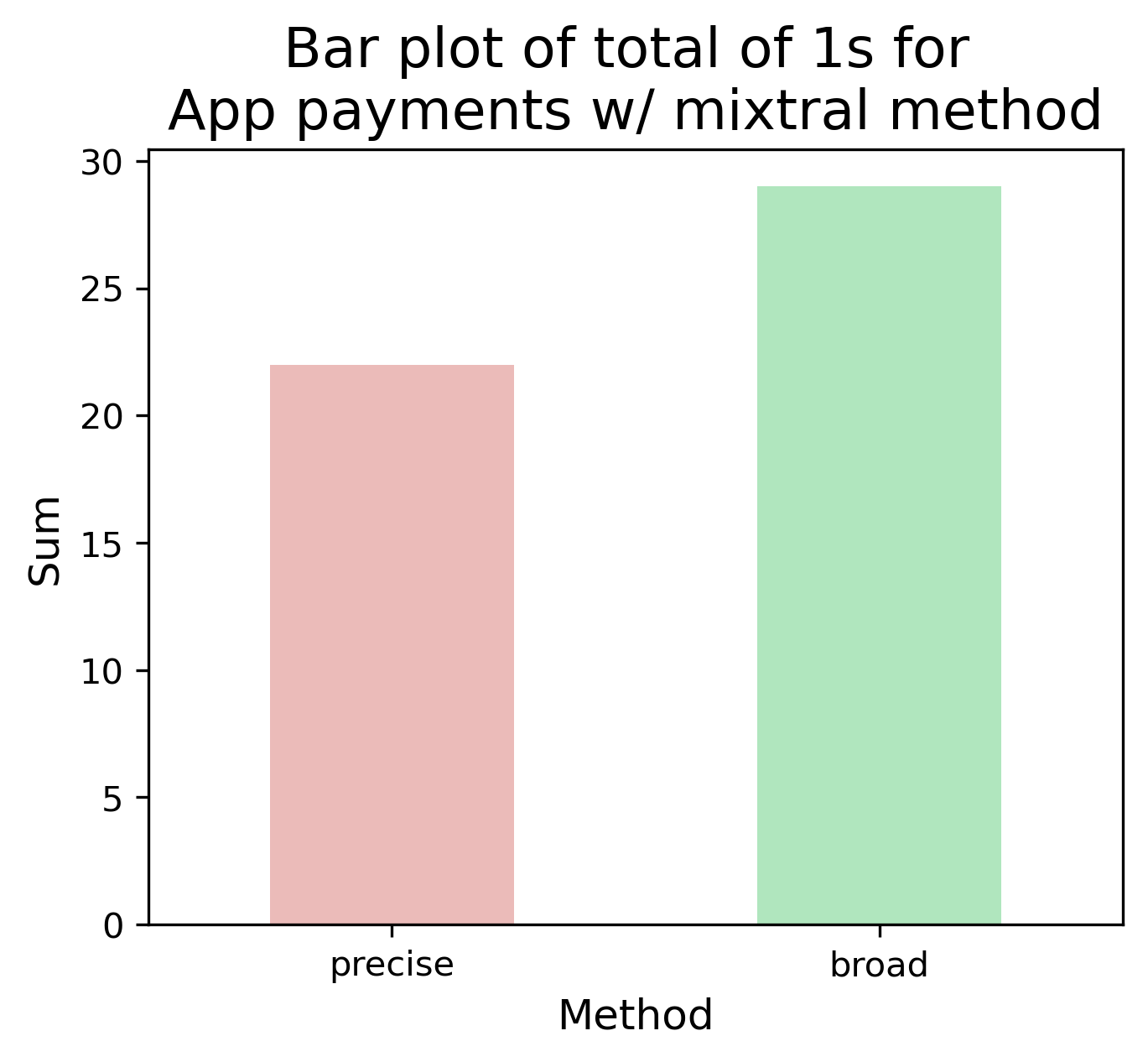 |
Figure: Plots to visualise the power of providing more terms.
Method vs. Method
In this section, I investigate methods against each other, and methods against the “gold standard” manual.
First, I look into the annotations within the task groups. We can see that the p-values via the Friedman tests (Table below) are all significant, with precise being the most significant, which could indicate fewer terms for annotating means these results have similar outcomes.
| Inner task | Methods | Friedman | P-value |
|---|---|---|---|
| precise | All | 43.01 | p<0.0001 |
| precise | Only computational | 38.17 | p<0.0001 |
| broad | All | 17.4 | p<0.01 |
| broad | Only computational | 16.18 | p<0.01 |
Table: Statistical tests the inner tasks when comparing results across all methods and then amongst computational.
Finally, I run the statistical tests for each task and method against the manual annotation, this is to reflect experiment 1. As we can see in the Table below, for the precise tasks, Gemma had the highest match with the manual in comparison to other methods. For the broader tasks, all methods improved with both Catch and Gemma having the highest agreement with manual.
| Task | Method | Accuracy | Kappa | Agreement | Correlation | Precision | Recall | F1-score |
|---|---|---|---|---|---|---|---|---|
| precise | catch | 0.82 | 0.26 | Minimal | 0.38 | 1 | 0.18 | 0.31 |
| precise | gemma2 | 0.9 | 0.71 | Moderate | 0.71 | 0.77 | 0.77 | 0.77 |
| precise | llama | 0.81 | 0.27 | Minimal | 0.33 | 0.71 | 0.23 | 0.34 |
| precise | mixtral | 0.8 | 0.42 | Weak | 0.42 | 0.55 | 0.55 | 0.55 |
| broad | catch | 0.93 | 0.81 | Strong | 0.82 | 0.78 | 0.95 | 0.86 |
| broad | gemma2 | 0.95 | 0.86 | Strong | 0.86 | 0.84 | 0.95 | 0.89 |
| broad | llama | 0.9 | 0.69 | Moderate | 0.69 | 0.83 | 0.68 | 0.75 |
| broad | mixtral | 0.87 | 0.66 | Moderate | 0.67 | 0.66 | 0.86 | 0.75 |
Table: Statistical tests on each method when compared to manual annotation for each inner task.
| A | B |
|---|---|
 |  |
 | 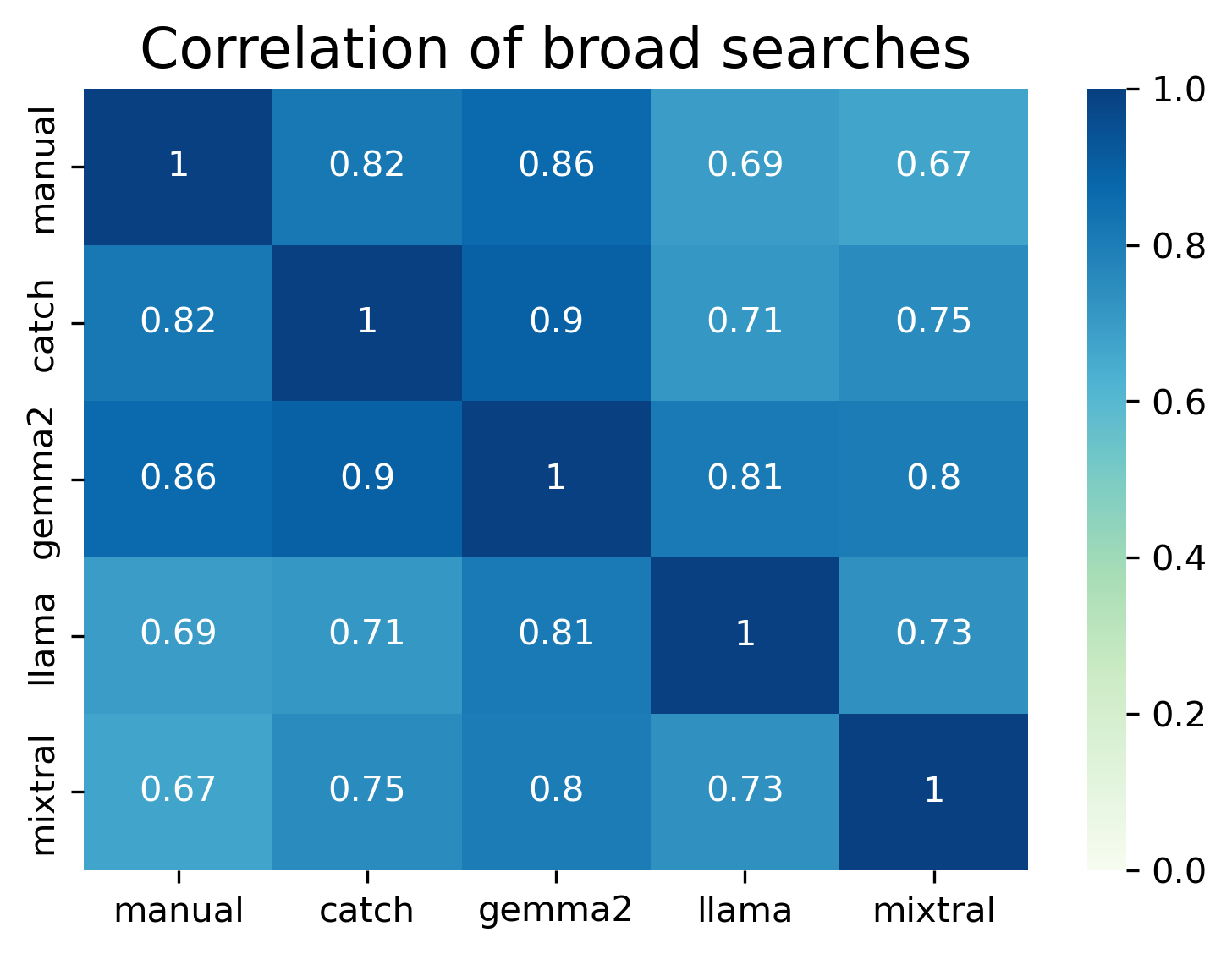 |
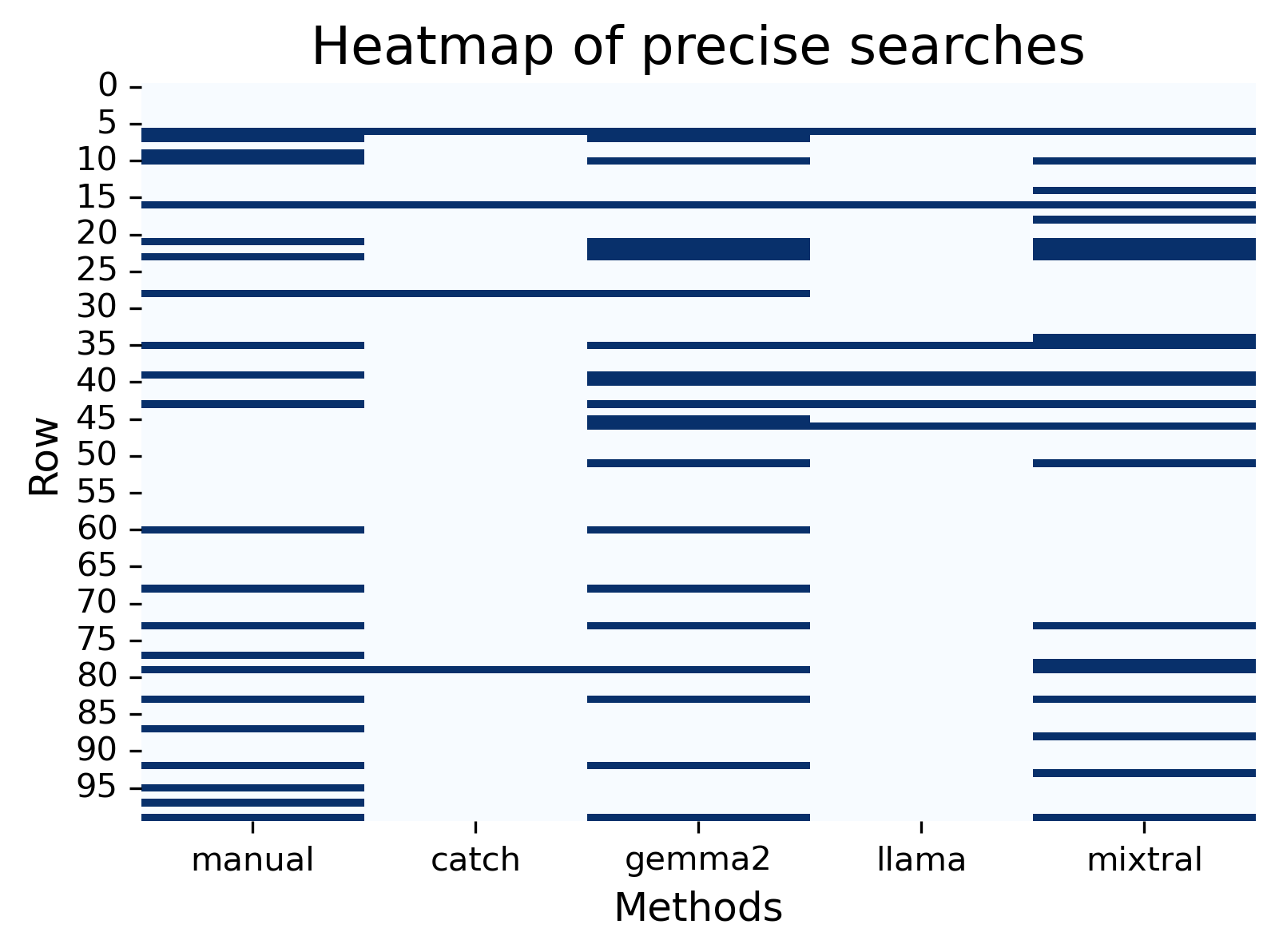
Figure: Plots to visualise the results and differences within the tasks. (A) Precise. (B) Broad.
Discussion
These experiments - although small - have shown how straightforward it can be to conduct annotation tasks. The move to computational methods means computers are doing a heavier bulk of the work, in such a shorter time, but we shouldn’t ignore the importance of statistical tests for validation, specifically against some manual annotation to highlight how reliable and accurate methods are.
I manually annotated a series of reviews for an App and then used NLP tools and LLMs to do the same task. Although manually annotating text is often considered the “gold standard”, it can be quite a time-consuming, draining task and users may make mistakes - as I did - despite the small sample size.
The first limitation of this study is that my opinions can be subjective. Moreover, Catch annotated the exact thing I asked for, this introduces bias: I developed Catch and I know its capabilities despite wanting to see how it compared to the novel LLMs. Regardless, we saw that LLMs sometimes considered context/related words for annotation - does this mean I missed vital information, despite the LLM ignoring the direct request? Can we reliably use LLMs if they do more than what was asked?
For each experiment, there was a topic of interest: a word and corresponding synonyms. I chose these synonyms, I did a quick Google search, and more were curated from the text after my annotations. Are the synonyms correct? Could I be missing more? Are there any hidden synonyms the LLMs used?
Without synonyms, Catch has a poor performance, concluding that Synonyms are invaluable for these sorts of NLP tasks. This is why synonym extraction tasks are useful (see Jabberwocky’s Bite function). For Catch to be even more useful, one would probably need to include common misspellings or abbreviations. Catch included functions for text cleaning in order to annotate, a user can modify this to suit their objective.
In contrast, LLMs take text directly - without any cleaning or formatting - as the models are trained on unstructured text. However, as mentioned, the models often “ignored” the request and annotated posts if similar words are included: sometimes incorrect, sometimes correct. Furthermore, LLMs tokenise words for processing and so this task of exact word matching can lead to inconsistencies.
To continue with the LLM request issue: these LLMs may be trying to “over complicate” the request and look for a “deeper” meaning: these models are overfitting! These additional annotations from the models means they are involving semantics, and although could be correct, is going against the request. It is important to note that some models, specifically Mixtral, are designed for more complex tasks and perhaps a little “overkill” for these “simple” experiments, or perhaps need more optimisation - which may also explain why Mixtral’s sentiment analysis had a stronger agreement with the manual.
Highlighting again about manually annotating being a time-consuming task, Catch took mere seconds to annotate whilst the LLMs - although still half the time compared to manual - took around 3 minutes for each word (+synonyms). I cannot fairly compare these results due to the API request limits. In future we can consider using the TensorFlow toolkit to run the LLMs locally via GPU which would drastically speed these annotation tasks. Some other things to consider is the model choice - I chose these based on what was available from GroqCloud and choose from different developers. In reality with a subscription, I can access more advanced models and the API requests will be faster.
Catch and Gemma consistently had better agreement with the manual annotation, even highlighting some posts that the manual, I, missed. Catch and Gemma also had strong agreements amongst each other. Despite these agreements, Gemma typically searched more broadly. Synonym choice, again, is important: although more were available for “update” resulting in better performance for Llama, it seemed that Catch and Gemma picked up more posts than necessary. However in experiment 3’s broader search, all methods had improved results with more synonyms.
Before finishing with some notes on LLMs, to briefly discuss the sentiment analysis, it seemed that each method moderately agreed with the manual annotation and scored in their own way. Although I made a mistake in one, I would say a user’s opinion is more reliable than a computer’s.
And finally, LLMs require a strong prompt.
You might have noticed that in the requests, I specifically had to note: Your response should only have the necessary data of a... this is because LLMs would respond with an introductory response, e.g. Here's the result based on whether <word> is mentioned in the sentence....
Moreover, for the sentiment analysis, I found the LLM would provide a score unless I specifically included the following statement: do not bother with the sentence if a word of interest is not present.
This was one of the drawbacks of LLMs: having to wrangle with the prompt.
Conclusion
With manual annotation we can review posts ourselves: we can investigate on a more granular level and consider context (sarcasm), synonyms, and misspellings or abbreviations. However, humans can make mistakes, and mistakes can become more frequent with more data: more effort is needed and so annotating becomes an exhaustive task.
NLP tools on the other hand are much faster and can handle larger volumes of data more efficiently. Yet may not consider the wider context. To tap into the full potential of these tools, one needs to have prerequisite knowledge of synonyms, common misspelling, or abbreviations. The effectiveness of these tools may depend on parameter fine-tuning. For example, one needs knowledge in text cleaning and other unstructured text formatting methods to know if the text should be cleaned more harshly or if lemmatisation is appropriate.
LLMs have thought beyond the request prompts: doing more than what was required by considering context and semantics in their responses. With sufficient computational resources they can be extremely useful. But one should consider the complexity of the task before using LLMs. LLMs themselves admit they can make mistakes: these models’ patterns could be built on unreliable sources.
Validation is invaluable though, so going forward, manual work is essential to ensure the work is accurate and reliable.
- Code
- to see the code, you can visit the GitHub repository: Catching LLMs.
References
Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, et al. Language Models are Few-Shot Learners. arXiv. 2020. Available: https://splab.sdu.edu.cn/GPT3.pdf ↩︎
Pendleton S, Gkoutos G. Jabberwocky: an ontology-aware toolkit for manipulating text. Journal of Open Source Software. 2020;5: 2168. doi:10.21105/joss.02168 ↩︎